
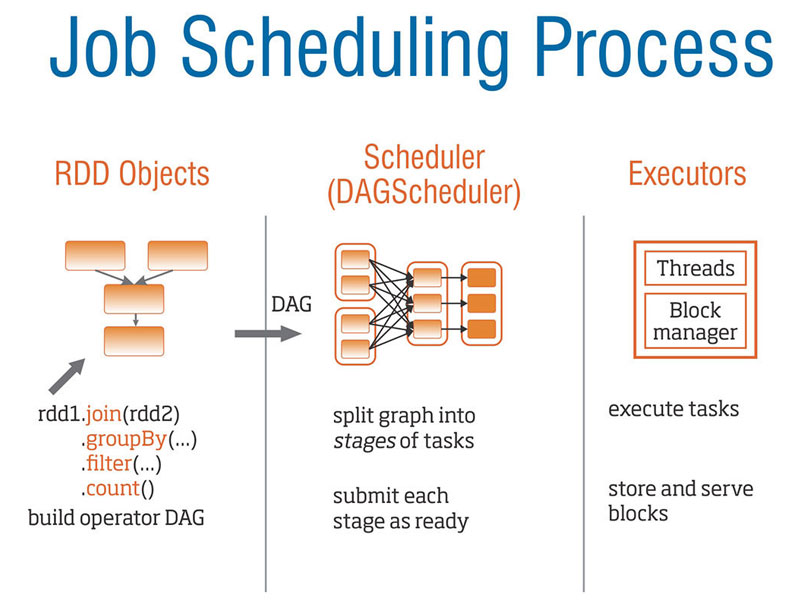
When an Apache Spark job is run then a DAG (Directed Acyclic Graph) of operators is created, then it is split into a set of Stages, which are further divided into a set of Tasks as shown in the below image. Apache Spark job is split into stages based on the data shuffling (moving data) across machines. Shuffling the data is a costly affair and less the data shuffled, the faster the job will be completed.
 Here is a simple WordCount Python program which finds out how many times a particular word is repeated in the given input data.
Here is a simple WordCount Python program which finds out how many times a particular word is repeated in the given input data.
from pyspark import SparkConf
from pyspark import SparkContext
conf = SparkConf().setMaster("spark://myubuntu:7077").set("spark.eventLog.enabled", "true")
.set("spark.eventLog.dir", "/home/myubuntu/Installations/spark-1.5.2-bin-hadoop1-scala2.11/eventLogs")
sc = SparkContext(conf=conf)
wordCount = sc.parallelize(["spark is cool", "spark is fast", "spark is hip"]).flatMap(lambda line : line.split())
.map(lambda word : (word, 1)).reduceByKey(lambda a, b: a + b)
print wordCount.collect()
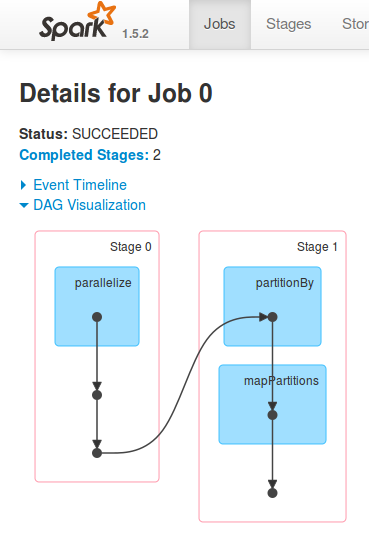
For the above program, below is the visualization of the different stages and tasks. Note that there are multiple stages and the data has to be shuffled because of the reduceByKey() aggregation. The below DAG is not automatically generated in the Spark console, ‘spark.eventLog.enabled’ and the ‘spark.eventLog.dir’ properties have to be set as shown in the above program. The properties can be set either in a programmatic way or by using the Spark configuration files.
Once the properties are set, the visualization, as shown above, will help in fine-tuning the Spark program. Note that less the less the number of stages, less the shuffling of the data between machines, less the time is taken for the Spark job to be completed. Look out for more tips around the Apache Spark framework.
