




If Big Data Analytics fascinates you and you wish to make a career out of it, then learning about Apache Hadoop Development is a professional imperative. Not only does it help you in flourishing your skills but also, helps you to take your career trajectory in the upward direction.

It is natural to wonder about the sources of such huge amounts of data. Here are some statistics to answer this concern–
- 700 petabytes of data are processed each month by Google alone.
- Facebook hosts 10 billion photographs which require as large as 1 petabyte of data space.
- 1 terabyte of data is generated by NYSE every day.
- Websites like Linkedin and Google+ are always in need of millions of terabytes each day.
For such large volumes of information, a server which would be able to handle all this was needed and the answer was found in Apache Hadoop. Conceptualized and created by Doug Cutting, It is an open source software framework. Hadoop is primarily used for storing and processing large volumes of Java-written data. The framework is capable of analyzing and processing high volumes of sorted or unsorted data. There are certain key steps listed below by employing which you can master Big Data Hadoop Development
CORE COMPONENTS
MapReduce– In order to write distributed applications a parallel programming model – MapReduce is required. Applications like these are devised at Google due to its capacity to process huge multi-terabyte data-sets on thousands of nodes of product hardware. MapR works on Hadoop.
It is quite easy to understand how MapReduce works. There is a given list of records which are represented in pairs. As the name suggests MapReduce is divided into two phases – a Map phase and a Reduce phase. The distribution of records is not in an orderly fashion but each of them is processed individually as a separate piece. This happens in the Map phase. On the other hand, in the Reduce phase, the records with similar keys are arranged together and thereafter, processed in the same computing node. This is how results are derived in the end.
Hadoop Distributed Filing System
It consists of a fault-tolerant distributed file system whose design is such that it converts large industrial servers into a big storage pool. This is known as HDFS. Based on the Google File System, it provides large volumes of data which are spread across numerous machines. HDFS lends high bandwidths all through the cluster of machines. The data in HDFS is duplicated at multiple nodes which results in better computing performance and protection.
TWO MODULES OF HADOOP DEVELOPMENT
Besides the two components discussed above, It comprises of the following two modules –
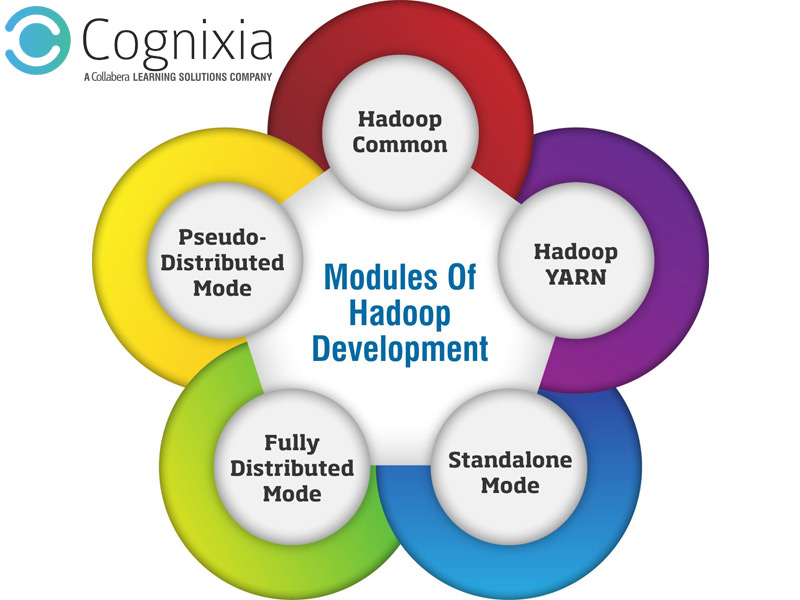
Hadoop Common
It is Commonly referred to the Java libraries and utilities which other Hadoop modules need.
Hadoop YARN
Hadoop YARN is a framework developed by Apache to be used for group resource management and job scheduling.
THREE MODES OF HADOOP DEVELOPMENT
Standalone Mode
When Hadoop is configured on a single machine it is referred to as Standalone Mode. The single machine on which it is configured is called Ubuntu which acts as the host. The name standalone is given to it as it is quite simple and doesn’t need any significant alterations.
Fully Distributed Mode
In a fully distributed mode environment, the virtual machine is distributed on real-time quite similar to as it happens in pseudo-distributed mode.
Pseudo-Distributed Mode
In this mode, Hadoop is configured on multiple machines – one of these machines acts as a master machine and the remaining are referred to as slaves.
ENVIRONMENT
Many software are required to be installed before you start using it. An absence of these software hinders the working of Hadoop.
- Ubuntu 10.10
- JDK 6 or above
- Hadoop – 1.1.2
- Eclipse
This might come across as a tedious job but it’s very flexible and easily scalable. However, there might be some issues in debugging the code which you write. This is one of the major challenges Developers are facing. But rather than identifying compilation errors, you should find out what might have happened in your cluster which will be different every time the application is run. But then, there are some effective applications which help you to remove bugs from your code.
Are you interested in Hadoop development? You do not need a college degree or a license to make a career as a Hadoop Developer. Cognixia provides one of the finest training programs. For further information, you can write to us.