




Tremendous advances in data capture, data processing, data transmission, and storage are enabling organizations to integrate their varied databases into the data warehouse. Data warehousing can be viewed as a central repository for maintaining all organizational data. Centralization of data is needed to maximize user access and analysis. Technological advances are making this vision a reality for many companies. Accordingly, due to advances in data analysis software, the users can access the data freely. Such data analysis software supports Data mining.
Data mining is a process of extraction of useful information and patterns from huge data. There is an urgent need for a new generation of computational theories and tools to assist humans in extracting useful information (knowledge) from the rapidly growing volumes of digital data. These theories and tools are the subjects of the emerging field of knowledge discovery in databases (KDD). While data mining and KDD are often treated as the same words but in reality, data mining is an integral step in the KDD process.
The KDD process is interactive and iterative, involving numerous steps.
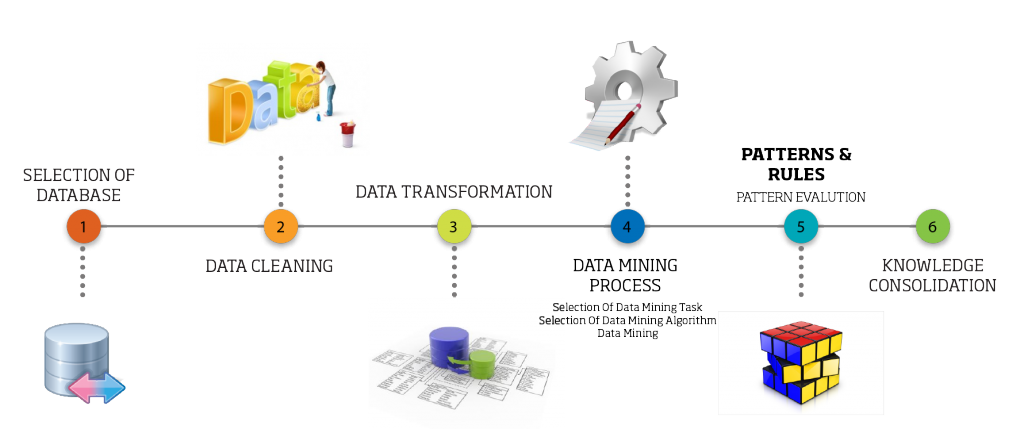
- Selection of Dataset: Select a data set or subset of data or data samples, on which data analysis will be performed to get useful information. Make sure there should be enough quantity of data to perform data mining.
- Data cleaning: Data cleaning is the step where noise and irrelevant data are removed from the large data set. Basically, in data cleaning, the duplicate records are removed, missing values are filled with correct values, noisy data are removed, data format are standardized, data are updated in a timely manner and so on.
- Data transformation: With the help of dimensionality reduction or transformation methods, the number of effective variables is reduced and only useful features are selected to depict data more efficiently based on the goal of the task. In short, data is transformed into appropriate form making it ready for data mining step.
- Selection of data mining task: Based on the objective of data mining, an appropriate task is selected. Some common data mining tasks are classification, clustering, association rule discovery, sequential pattern discovery, regression and deviation detection. Any of these tasks can be selected based on the need to predict information or describe information.
- Selection of data mining algorithm: Appropriate method(s) is to be selected for looking for patterns from the data. The model and parameters need to be decided on the basis of the method. Some popular data mining methods are decision trees and rules, relational learning models, example-based methods etc.
- Data mining: Data mining is the actual search for patterns from the data available using the selected data mining method.
- Pattern evaluation: This is a post-processing step in KDD which interprets mined patterns and relationships. If the pattern evaluated is not useful, then the process might again start from any of the previous steps, thus making KDD an iterative process.
- Knowledge consolidation: This is the final step in Knowledge Discovery in Databases (KDD). The knowledge discovered is consolidated and represented to the user in a simple and easy to understand format. Mostly, visualization techniques are being used to make users understand and interpret information.
Even though the above is the basic steps but still many steps can be combined during the actual process. During this whole process, we analyze what we are mining data to get useful information or knowledge. So, eventually, knowledge mining would be the more appropriate term rather than data mining. This post throws some insight on Knowledge Discovery Process.