




The main aspect of the Big Data is to store and process huge amounts of data in a cost-effective way. The same is achieved by using a lot of commodity machines, based on the size of the cluster this varies from 10’s of machines to 1000’s of machines as shown below.

For those who are getting started with Big Data cluster not only having a lot of machines is unnecessary, but also it doesn’t make sense from a commercial perspective. The best way is to start using a single Virtual Machine as discussed in the previous blog. With the laptops and desktops becoming more powerful and cheap day by day, it’s also possible to set up a small Big Data cluster on a single machine using virtualization. It might be not possible to do complex analytics on some huge data sets, but would be good enough to get started for executing simple programs on smaller datasets.
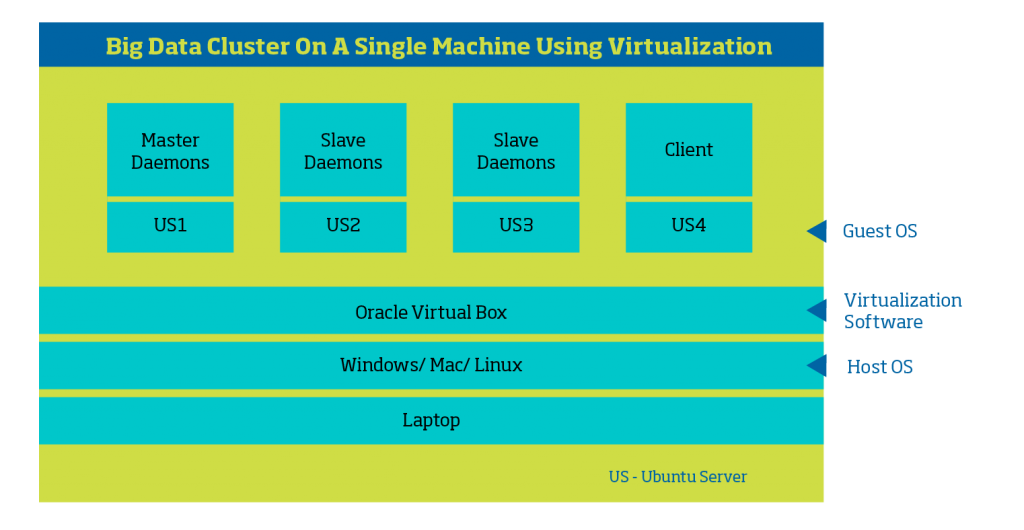
Virtualization software like Oracle VirtualBox enables running multiple OS on the same machine. Each of the OS can be allocated appropriate resources based on the services running on that particular OS as shown below. The client can be used to put some small datasets in HDFS and execute MapReduce or Spark programs. To speed up setting up the cluster, the first guest OS can be installed manually and the rest of the systems can be cloned using the feature provided by the virtualization software. Also, to make the cluster a bit more responsive some of the services (like the printer, scanner etc) which are not required can be disabled and also some of the start-up applications disabled on the guest OS. In the below set up a total of five OS are being run on a single machine, wherein a bit of fine-tuning will help.
The problem with the above approach is that each of the guest OS will be running a full Linux OS which is not really efficient. So, comes the containers providing the virtualization at the OS level. The process running within the context of a container think that it has got the entire machine and also, multiple OS need not be run at the same time. One OS per machine should be good enough. The container approach though efficient doesn’t provide the same level of isolation when virtualization software like Oracle VirtualBox is used.
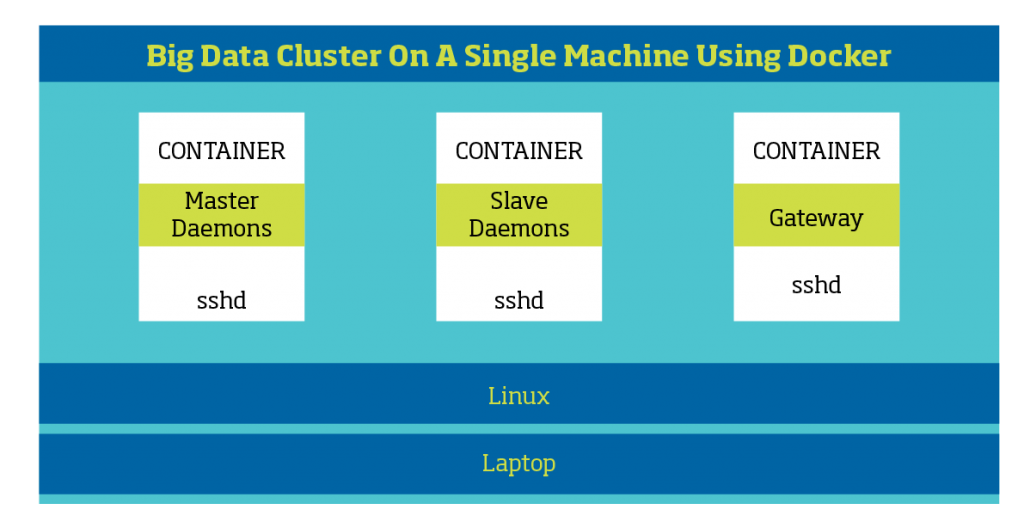
The Cognixia Big Data developer course will discuss on setting up a cluster in different configurations at a high level, while the Big Data Administration course will delve into a bit more detail.